파이썬으로 살펴보는 아키텍처 패턴 (4)
이 내용은 “파이썬으로 살펴보는 아키텍처 패턴” 을 읽고 작성한 내용입니다. 블로그 게시글과, 작성한 코드를 함께 보시면 더욱 좋습니다.
4장은 해당 코드를 살펴봐주세요. 코드 링크
4장 API와 서비스 계층
이런 구조를 만들 것이다
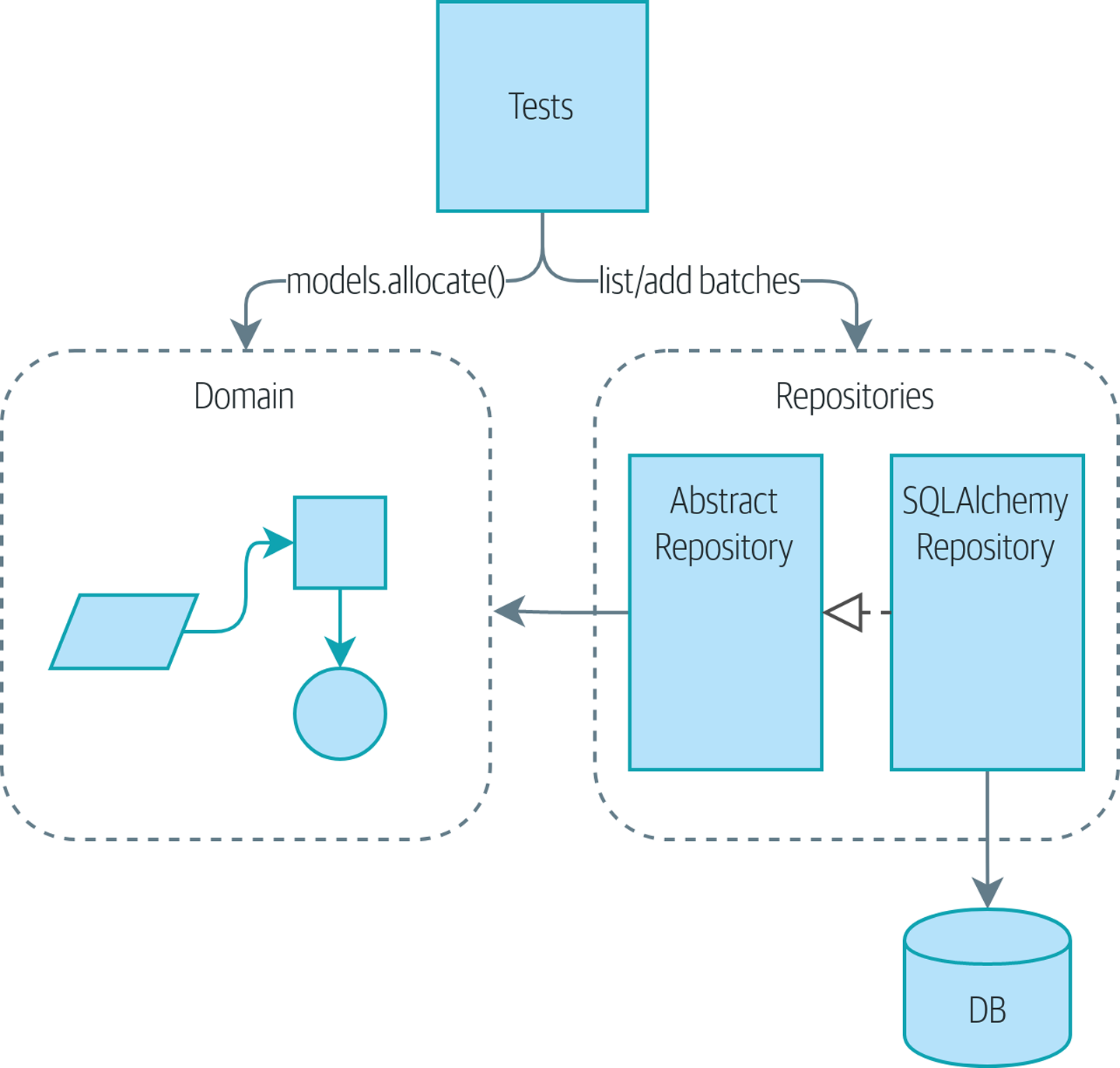
이 장에서는 오케스트레이션 로직, 비즈니스 로직, 연결 코드 사이의 차이를 이해한다. 워크플로우 조정 및 시스템의 유스케이스를 정의하는 서비스 계층 패턴을 알아본다.
테스트도 살펴본다. 서비스 계층과 데이터베이스에 대한 저장소 추상화를 조합할 것이다. 이를 통해 도메인 모델 뿐 아니라 유스케이스의 전체 워크플로우를 테스트할 것이다.
테스트할 때 보면 프로덕션 코드는 SqlAlchemyRepository 를 쓰고, 테스트할 때는 FakeRepository를 쓰게 한다.
4.1 애플리케이션을 실세계와 연결하기
이게 가장 빨라야한다! MVP니까…
도메인에 필요한걸 만들고 주문할당(allocate)을 하는 도메인 서비스도 만들었고, 리포지토리 인터페이스도 만들었다…
그러면 다음 할 일은 아래와 같다:
- 플라스크를 써서
allocate도메인 서비스 앞에 API 엔드포인트를 둔다. DB 세션과 저장소를 연결한다. 이렇게 만든 시스템은 e2e 테스트와 빠르게 만든 SQL 문으로 테스트한다. - 서비스 계층을 리팩토링한다. 플라스크와 도메인 모델 사이에 유스케이스를 담는 추상화 계층을 만든다. 몇 가지 서비스 계층 테스트를 만들고
FakeRepository를 써서 코드를 테스트한다. - 서비스 계층의 기능을 여러 유형의 파라미터로 실험한다. 원시 데이터 타입으로 서비스 계층의 클라이언트 (테스트와 API)를 모델에서 분리해본다.
4.2 첫 E2E 테스트
실제 API 엔드포인트(HTTP)와 실제 DB를 사용하는 테스트를 한, 두개정도 짜고 리팩토링 또 한다.
일단 처음엔 어쨌거나 만든다. 랜덤 문자열을 생성하고, DB에 row를 넣는 함수를 실제로 짠다.
4.3 직접 구현하기
책에선 플라스크를, 나는 FastAPI를 통해서 짰다. 그런데 이 테스트의 한계는 DB커밋을 해야한다는 점이다.
4.4 DB 검사가 필요한 오류조건
이런 케이스는 DB 측의 데이터 무결성 검사다. 도메인 서비스 호출 전에 캐치해야한다.
- 도메인이 재고가 소진된 sku에 대해 예외가 발생하면?
- 존재하지 않는 sku에 대한 예외처리는?
근데 이 방어로직을 API에 넣으면 E2E 테스트 갯수가 점점 많아지게되고 역피라미드형 테스트가 된다. 테스트코드도 꼬인다…
따라서, API에 있던 일부 로직을 유스케이스로 빼고, 이를 테스트하기 위해 FakeRepository를 쓸 때가 왔다.
4.5 서비스 계층 소개와 서비스 계층 테스트용 FakeRepository 사용
API는 가만보면 오케스트레이션이다. 저장소에서 뭐 갖고와서 DB 상태에 맞게 검증도 하고 오류 처리도 하고, 성공적이면 DB에 값도 커밋한다. 근데 이런 작업은 API하고는 관련이 없다.
FakeRepository를 이용해서 진짜 손쉽게 AAA 테스트코드를 구현했다FakeSession을 이용해서 세션도 가짜로 만든다. 6장서 리팩토링할거다
→ 당연하겠지만 커밋도 테스트 대상이다
4.5.1 서비스 함수 작성
이런 구성을 가져간다.
- 저장소에서 객체를 가져온다
- 애플리케이션이 아는 세계를 바탕으로 요청검사/검증(assertion) 한다
- 도메인 서비스를 호출한다
- 모두 정상실행했다면 변경된 상태를 저장/업데이트 한다
4.5.2 deallocate 을 만든다면?
- 제 1 사이클: 일단 짜자
- deallocate하는 도메인 로직부터 짜고 테스트한다
- 저장소 로직을 만든다
- 유스케이스를 만든다
- e2e를 만든다
- 제 2 사이클: 3장에서 본 내용을 적용해보자…
- 올바른 추상화를 하고있나?
- 바운더리가 어디어디 끊어지고, 이를 함수레벨로 나눌 수 있을까?
UoW 하고나서 다시 할거다…
4.6 왜 서비스라 부름?
여기서 서비스라 부르는건 두 가지가 있다:
- 도메인 서비스
- 도메인 모델에 속하지만, 엔티티/VO에 속하지 않는 로직을 부르는 이름이다.
- E.g., 쇼핑카트 애플리케이션을 만든다고 할 때
- 도메인 서비스로 세금 관련 규칙을 구현한다
- 모델에서는 중요하지만, 세금 관련만을 위한 영속적 엔티티를 빼지 않으려고 하는 것이다
- 구현한다면
TaxCalculator라는 클래스나calculate_tax같은 함수들로 처리하면 될 것이다
- 서비스 계층
- 외부 세계로부터 오는 요청을 처리해 연산을 오케스트레이션 한다.
- 아래 단계를 수행하여 애플리케이션을 제어한다
- DB에서 데이터를 얻는다
- 도메인 모델을 업데이트한다
- 바뀐 내용을 영속화한다
- 비즈니스 로직과 떼어내서 프로그램을 깔끔하게 두자
4.6.1 처리과정
- 또 리팩토링…
- 개별 테스트도 메모리로 하면 되고, 값 준비해야되는걸 픽스처로 처리하자.
yield 전후로 setup, teardown으로 두자
- DB initialize 로직을 실제 앱 실행, 테스팅 두가지로 나누고 providers override로 처리하자
-
이러면 의존성 역전이 되는건지 살펴보자
This helps in testing. This also helps in overriding API clients with stubs for the development or staging environment.
Provider overriding , Dependency Injector
되는듯!
-
일단 너무 많은기능을 한번에 할려는 것 같으니 구획을 좀 나눠보자
- 테스트 구동 프로시저
AsyncClient로 앱 구동함 → DB처리를 여기서도 함- DB처리
- ‘엔진’ 생성
- 메타데이터를 통한 테스트DB 생성
- SQLAlchemy의 ‘세션’ 생성
- 앱 구동 프로시저 (영 불안한 코드…)
- ORM 사용을 위한 SQLAlchemy의 ‘매핑’ 수행
- 세션메이커 만들고 필요할 때마다 yield 해가게 세팅함
- 테스트 구동 프로시저
-
- 도메인 서비스 관련 처리과정
- 테스트를 나눠서 성공했다
- 서비스 계층 처리과정
- UoW 로 나누면서 해결할거다. 지금은 세션의 아래 문제 때문에 못한다
- 처음 선언시 engine 주소
<pt1.ch04.adapters.postgres.AsyncSQLAlchemy object at 0x000002A79A5C7670>- 테스트 환경서…
<pt1.ch04.adapters.postgres.AsyncSQLAlchemy object at 0x000002A79AA650C0>- 다시 로직에서…
<pt1.ch04.adapters.postgres.AsyncSQLAlchemy object at 0x000002A79A5C7670> - 즉, 주소가 다르니까 거기서 갖고와봤자… 이런걸로 진 빼지말고 개선하면서 해결하자
- ❓이런 상황에서는 어떻게 시간분배를 해야할까? 이건 어디에 어떻게 물어보면 좋을까?
- UoW 로 나누면서 해결할거다. 지금은 세션의 아래 문제 때문에 못한다
4.7 디렉토리 구조를 잡자
여기서는 책에서 제시하는 구조를 일단 따른다. 주관은 지식이 생긴 후에 갖추는 것이 맞다고 생각한다.
domain→ 도메인 모델- 클래스마다 파일을 만든다
- 엔티티 VO, Aggragate에 대한 부모 클래스도 여기에
- exception이나 command, event도 여기
service_layer→ 서비스 계층- 서비스 계층 예외가 추가가능
- uow를 여기…
adapters→ ‘포트와 어댑터’ 용어에 사용된 어댑터- 외부 I/O를 감싸는 추상화(redis_client.py)를 넣음
- secondary adapter, driven adapter, inward-facing adapter 라고 일컫는다
entrypoints→ 애플리케이션 제어 시점, ‘포트와 어댑터의’ 어댑터- primary adapter, driving adapter, outward-facing adatper 라고 일컫는다
포트는? 어댑터가 구현하는 추상 인터페이스이다. 포트를 구현하는 어댑터와 같은 파일 안에 포트를 넣는다.
4.8 마무리
- API 엔드포인트가 얇고 짜기 쉬워진다 → 웹 기능만 모아놨다
- 도메인에 대한 API 정의를 했다. 논리적인 작업을 통으로 모아놓은 엔트리포인트다
- 서비스 계층의 장점은 아래와 같다
- 테스트를 ‘높은 기어비’로 작성할 수 있다
- 도메인 모델을 적합한 형태로 리팩토리링 할 수 있다
- 이를 활용하여 유스케이스를 제공할 수 있는 한 이미 존재하는 많은 테스트를 재작성하지 않고도 새 설계를 테스트할 수 있다
- 테스트 피라미드도 (아직까지) 나쁘지 않다
4.8.1 DIP가 어떻게 돌아가는지….
서비스 계층이 어떻게 의존하는지 다시 살펴보자.
서비스 계층은 도메인 모델, AbstractRepository 를 받는다.
async def allocate(
line: model.OrderLine,
repo: repository.AbstractRepository,
session,
) -> str:
""" batches를 line에 할당한다.
FYI,
의존성 역전 원칙이 여기 들어감에 유의!
고수준 모듈인 서비스 계층은 저장소라는 추상화에 의존한다.
구현의 세부내용은 어떤 영속 저장소를 선택했느냐에 따라 다르지만
같은 추상화에 의존한다.
:param line:
:param repo:
:param session:
:return:
"""
batches = await repo.list()
if not is_valid_sku(line.sku, batches):
raise InvalidSku(f'Invalid sku {line.sku}')
batchref = model.allocate(line, batches)
await session.commit()
return batchref그죠?
프로덕션 상에서는 SqlAlchemyRepository를 플라스크가 “제공” 하면 DIP가 이루어진다.
여기까지의 트레이드오프를 살펴보자
| 장점 | 단점 |
|---|---|
| 애플리케이션의 모든 유스케이스를 넣을 유일한 위치가 생긴다 | 앱이 순수한 웹앱일 경우, 컨트롤러/뷰 함수는 모든 유스케이스를 넣을 유일한 위치가 된다 |
| 정교한 도메인로직을 API뒤로 숨긴다. 리팩토링이 쉬워진다 | 서비스 계층도 또다른 추상화 계층이다 |
| ‘HTTP와 말하는 기능’을 ‘할당을 말하는 기능’으로부터 말끔하게 분리했다 | 서비스 계층이 너무 커지면 anemic domain 이 된다. 컨트롤러에서 오케스트레이션 로직이 생길 때 서비스 계층을 만드는게 낫다 |
| 저장소 패턴 및 FakeRepository 와 조합하면 도메인 계층보다 더 높은 수준에서 테스트를 쓸 수 있다. 통합테스트 없이 개별 테스트가 가능해진다. | |
| (5장에서 더 자세히 보자) | 풍부한 도메인 모델로 얻을 수 있는 이익 대부분은 단순히 컨트롤러에서 로직을 뽑아내 모델 계층으로 보내는 것 만으로 얻을 수 있다. 컨트롤러와 모델 계층 사이에 또다른 계층을 추가할 필요가 없다. |
| 대부분의 경우 얇은 컨트롤러와 두꺼운 모델로 충분하기 때문이다. |
개선해야 할 점도 있다
- 서비스 계층 API가
OrderLine객체를 사용해 표현되므로, 서비스 계층이 여전히 도메인과 연관되어있다. 이 고리를 끊자. - 서비스 계층은 세션 객체와 밀접하게 결합되어 있다. UoW로 풀어보자.
끝으로
잘 되겠지… 하는 코드를 점차 없애자. 저기서 문제가 나면 어떻게 할 거야…
SQLAlchemy 2.0 쿼리 방안을 좀 익혀두자
SQLAlchemy 2.0 - Major Migration Guide — SQLAlchemy 2.0 Documentation
sqlite?
SQLite는 딱히 TRUNCATE TABLE이 없다. 그래서 DELETE FROM 으로 다 날리면 된다
한편 postgres에서 DB 테스트하고 날릴거면 nextval 시퀀스 초기화라거나 그런 부분들도 생각해야한다.