파이썬으로 살펴보는 아키텍처 패턴 (7)
이 내용은 “파이썬으로 살펴보는 아키텍처 패턴” 을 읽고 작성한 내용입니다. 블로그 게시글과, 작성한 코드를 함께 보시면 더욱 좋습니다.
7장은 해당 코드를 살펴봐주세요. 코드 링크
7장 애그리게이트와 일관성 경계
도메인 모델을 보면서 불변조건, 제약에 대해 다시 살펴보고 도메인 모델 객체가 개념적으로나 영속적 저장소 안에서나 내부적인 일관성을 유지하는 방법을 살펴본다1.
일관성 경계(consistency boundary)를 설명하며, 이를 통해 어떻게 유지보수 편의를 해치지 않으면서 고성능 소프트웨어를 만들 수 있게 도와주는지 살펴보자.
애그리게이트가 추가되면 도메인을 이런식으로 표현할 수 있게 된다
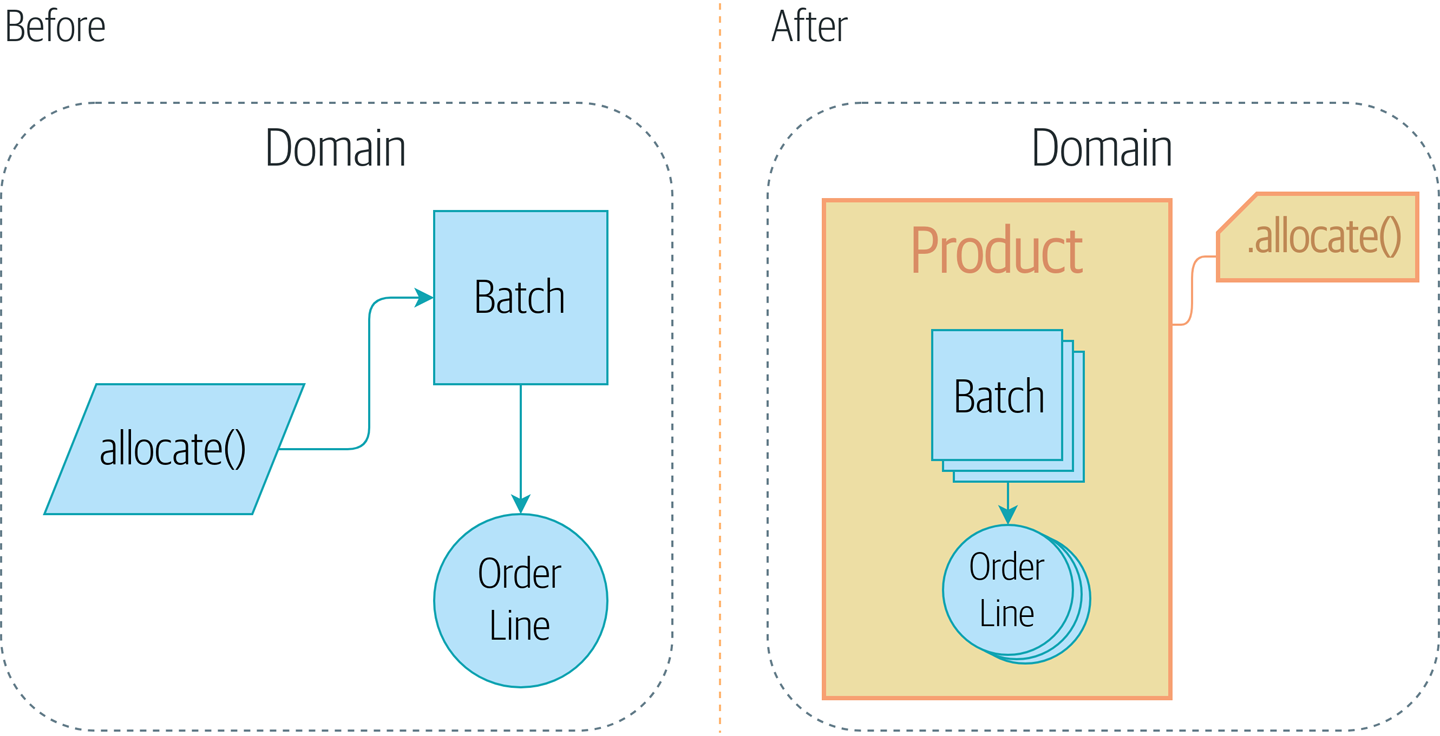
7.1 모든 것을 스프레드시트에서 처리하지 않는 이유
도메인 모델의 요즘은 무엇일까? 이걸로 얻는 근본적인 이득이 뭘까?
걍 스프레드시트로 다 하면 안되나? 어차피 사용자들은 하나로 다 되는거 엄청 좋아하는데.
많은 수의 기업운영이 CSV over SMTP 수준의 아키텍처에서 걍 머물러있다. 역으로 말하면 딱 그정도의 회사들이 버글버글하단 이야기다. 일단 잘되고 좋은데 일관성이 없어서 확장이 안된다.
예를 들어…
- 특정 필드는 누구만 볼 수 있도록 설정되어있는가?
- 누가 그 ‘누구’를 변경할 수 있는가?
- 의자를 -350개 주문하거나 식탁을 10M개 주문할 수 있나?
- 직원의 월급이 음수가 될 수 있나?
이런 건 일어나서도 안 된다. 도메인 로직은 이런 제약사항을 강제로 지키게 해서 시스템이 만족하는 불변조건을 유지하려는 목적으로 작성된다. 불변조건(*invariants)*은 어떤 연산을 끝낼 때 마다 항상 참이어야 하는 요소를 의미한다.
7.2 불변조건, 제약, 일관성
- 제약(constraint): 모델이 취할 수 있는 상태의 수를 제한
- 불변조건(invariants): 항상 참이어야 하는 조건
E.g., 호텔 예약 시스템을 작성한다면 중복 예약을 허용하지 않는 제약이 있을 수 있다. 이 제약은 한 객실에 예약 한 개만 있을 수 있다는 불변조건을 지원한다.
경우에 따라 규칙을 일시적으로 완화(bend)해야할 수도 있다. VIP가 예약하면 VIP의 숙박 기간과 위치에 맞춰 주변의 방 예약을 섞어야 할 수도 있다.
메모리상에서 예약을 섞는 동안 한 곳에 예약이 2개 이상 발생할 수도 있지만, 도메인 모델은 작업이 완료되면 불변성이 충족되는 최종 일관된 상태가 되도록 보장해야 한다. 모든 고객이 만족하는 방안을 못찾고 연산이 끝나면 안 되고 오류를 발생시켜야 한다.
다시 예시로 돌아가보자. 이 요구사항부터 시작해보자.
주문 라인은 한번에 한 배치에만 할당될 수 있다
이런 규칙은 불변조건을 만드는 비즈니스 규칙이다. 불변조건은 주문 라인이 0또는 1개의 배치에만 할당될 수 있고, 2 개 이상의 배치에 할당될 수는 없다는 것이다. 코드가 실수로 같은 라인에 대해 Batch.allocate() 를 두 가지 다른 배치에 호출하는 일이 없도록 해야한다. 현재까지의 코드에선 그런 명시적인 코드는 없다.
7.2.1 불변조건, 동시성, 락
비즈니스 로직의 다른 요구사항을 살펴보자
주문 라인 수량보다 더 작은 배치에 라인을 할당할 수는 없다
여기서의 제약조건은 배치에 있는 재고보다 많은 재고를 라인에 할당할 수 없다는 것이다. 이로 인해 두 고객에게 제품을 재고보다 더 많이 파는 일은 발생할 수 없다. 이 제약을 불변조건으로 바구면 가용 재고 수량이 0이상이어야 한다는 조건이 된다2. 시스템 상태를 업데이트 할 때마다 코드는 이런 불변조건을 어기지 않는지 확인해야 한다.
동시성(concurrency)를 도입하면 더 복잡해진다. 갑자기 재고를 여러 주문 라인에 동시에 할당할 수 있게 된다. 심지어 배치 변경과 동시에 주문라인을 할당할 수도 있다.
보통은 DB 테이블에 lock을 걸어서 해결한다. 두 연산이 동시에 일어나는 것을 방지하기 위함이다.
앱의 규모확장을 생각하면 모든 배치에 라인을 할당하는 모델은 규모를 키우기 어렵다는 사실을 깨닫는다(내 생각엔 이게 핵심 포인트다. 도메인을 알고 있다면/논의하다보면 이런 추론을 할 수 있어야 한다). 시간당 수만 건의 주문과 수십만 건의 주문 라인을 처리하려면 전체 테이블의 각 row에 lock을 거는 것 만으로는 안 된다. 이러면 데드락 상태에 빠질 수 있다.
7.3 Aggregate 이란?
주문 라인을 할당하고 싶을 때마다 DB에 lock을 걸 수 없다면 어떻게 해야할까? 시스템의 불변조건을 보호하면서 동시성을 최대한 살리고 싶다. 불변조건을 유지하려면 불가피하게 동시 쓰기를 막아야 한다. 여러 사용자가 DEADLY-SPOON 을 동시에 할당할 수 있다면 과할당이 이루어질 위험이 생긴다.
반면, DEADLY-SPOON 과 FLIMSY-DESK 를 동시에 할당할 수 없는 이유는 없다. 두 제품에 동시에 적용되는 불변조건이 없기 때문이다. 즉 서로 다른 두 제품에 대한 할당 사이에 일관성이 있을 이유는 없다.
애그리게이트(Aggregate) 패턴은 이런 긴장을 해소하기 위한 설계 패턴이다. 애그리게이트는 다른 도메인 객체를 포함하며 이 객체 컬렉션 전체를 한꺼번에 다룰 수 있게 해주는 도메인 객체다.
애그리게이트에 있는 객체를 변경하는 유일한 방법은 애그리게이트와 그 안의 객체 전체를 불러와서 애그리게이트 자체에 대해 메소드를 호출하는 것이다.
모델이 점점 복잡해지고 엔티티와 VO가 늘어나면서 각각에 대한 참조가 얽히고설킨 그래프가 된다. 따라서 누가 어떤 객체를 변경할 수 있는지 추적하기 어려워진다. 특히 모델안에 컬렉션이 있으면 어떤 엔티티를 선정해서 그 엔티티와 관련된 모든 객체를 변경할 수 있는 단일 진입점으로 삼으면 좋다3. 이러면 시스템이 개념적으로 더 간단해지고 어떤 객체가 다른 객체의 일관성을 책임지게 하면 시스템에 대해 추론하기 쉬워진다.
쇼핑몰 설계를 예로 들어보자. 장바구니(cart)는 좋은 애그리게이트가 된다. 장바구니는 한 단위로 다뤄야 하는 상품들로 이루어진 컬렉션이다. 중요한 점은 데이터 스토어에서 전체 장바구니를 단일 blob으로 읽어오고 싶다는 점이다. 동시에 장바구니 변경을 위해 요청을 두번 보내고 싶지도 않고 이상한 동시성 오류를 발생하게 하고싶지도 않다. 대신 장바구니에 대한 모든 변경을 단일 DB 트랜잭션으로 묶고싶다.
하지만 여러 고객의 장바구니를 동시에 바꾸는 유스케이스는 없다. 여러 장바구니를 한 트랜잭션 안에서 바꾸고 싶진 않다. 따라서 각 장바구니는 자신만의 불변조건을 유지할 책임을 담당하는 한 동시성 경계다.
애그리게이트는 데이터 변경이라는 목적을 위해 한 단위로 취급할 수 있는 연관된 객체의 묶음이다.
Eric Evans, 도메인 주도 설계(위키북스, 2011)
Evans에 따르면, 애그리게이트에는 원소에 대한 접근을 캡슐화한 루트 엔티티(장바구니) 가 있다. 원소마다 고유한 정체성이 있지만, 시스템의 나머지 부분은 장바구니를 나눌 수 없는 단일 객체처럼 참고해야 한다.
7.4 애그리게이트 선택
그렇다면 시스템에 어떤 애그리게이트를 써야할까? 내 생각엔 좋은 설계를 위해선 이걸 잘 정해야 한다고 본다. 애그리게이트는 모든 연산이 일관성 있는 상태에서 끝난다는 점을 보장하는 경계가 되기 때문이다. 이러한 사실은 소프트웨어에 대해 추론하고 이상한 경합지점을 방지할 수 있게 해준다. 서로 일관성이 있어야 하는 소수의 객체 주변에 경계를 설정하고자 한다. 성능을 위해선 경계가 더 작을 수록 좋다. 이런 경계에는 좋은 이름을 부여해주는 것 또한 필요하다.
애그리게이트 내부에서 다뤄야 하는 객체는 Batch 이다. 이 컬렉션을 뭐라고 부르는게 좋을까? 어떻게 시스템의 모든 배치를 내부에서 일관성이 보장되는 다른 섬들로 나눌 수 있을까?
- shipment?
- 선적엔 여러 배치가 들어갈 수 있다
- 모든 배치는 창고로 전달된다
- warehouse?
- 각 창고에는 여러 배치가 들어있다
- 모든 재고수량을 동시에 파악할 수도 있다
그런데 두 상품이 같은 창고에 있거나 같은 선적에 포함되어있어도 동시할당이 된다. 아까 위에서 이렇게 파악했다:
DEADLY-SPOON과FLIMSY-DESK를 동시에 할당할 수 없는 이유는 없다.
그런고로 상기 둘은 경계로 두긴 어렵다.
주문 라인을 할당할 때는 주문 라인으로 같은 SKU 에 속하는 배치에만 관심이 있다. 글로벌한 SKU stock 같은 개념이 필요하다. GlobalSkuStock 으로 할까? 근데 저자는 저 이름이 너무 촌스러워서 Product 로 하기로 했다4.
기존에는, 주문 라인을 할당하고 싶으면 모든 Batch 객체를 살펴보고 이들을 allocate() 도메인 서비스에 전달했다.
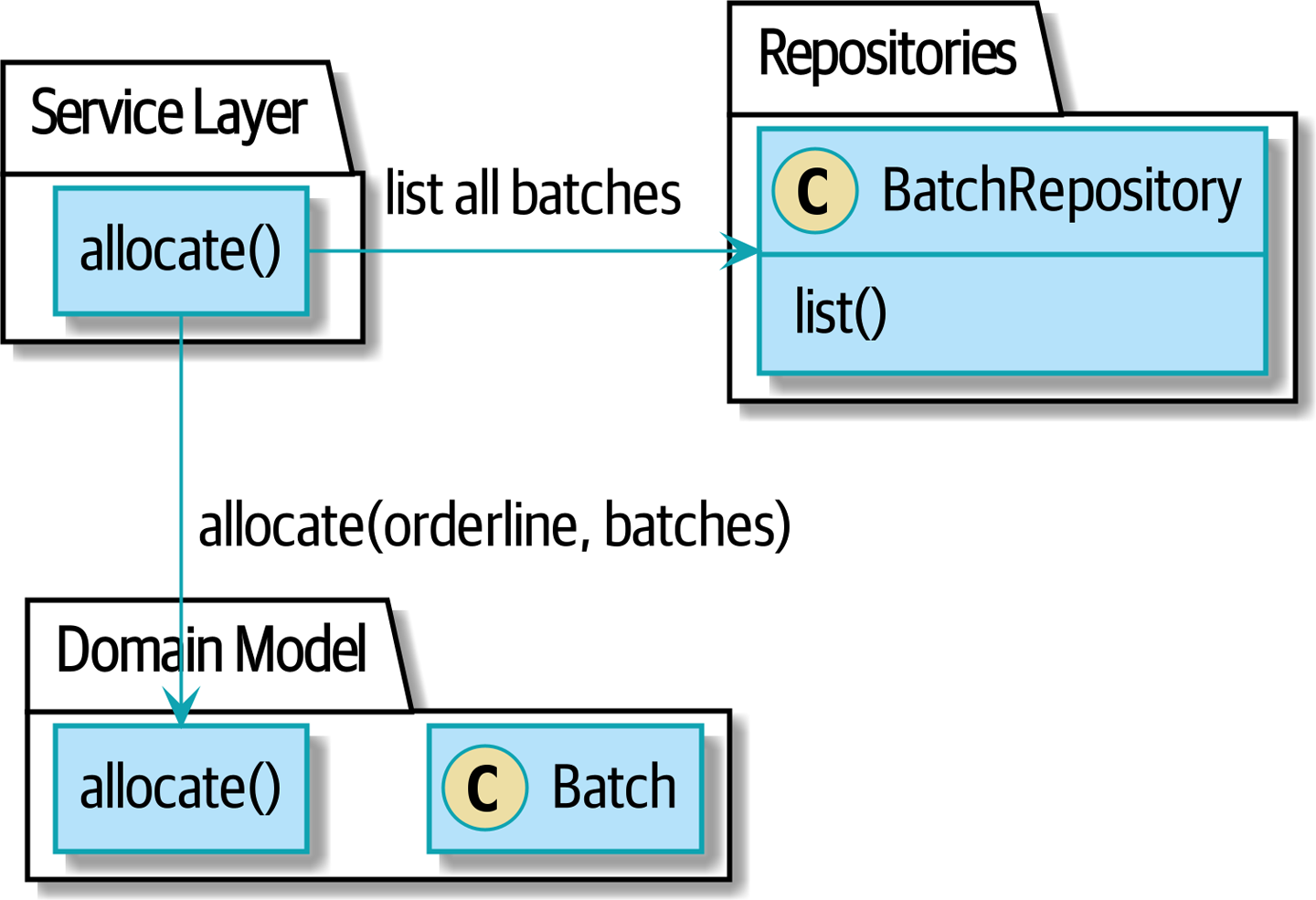
앞으로는 Product 객체한테 일임할 것이다. 이 객체는 주문 라인에서 특정 SKU를 표현한다. Product 객체는 자신이 담당하는 SKU에 대한 모든 배치를 담당한다. allocate() 메소드를 Product에 대해 호출하도록 열어둘 것이다.
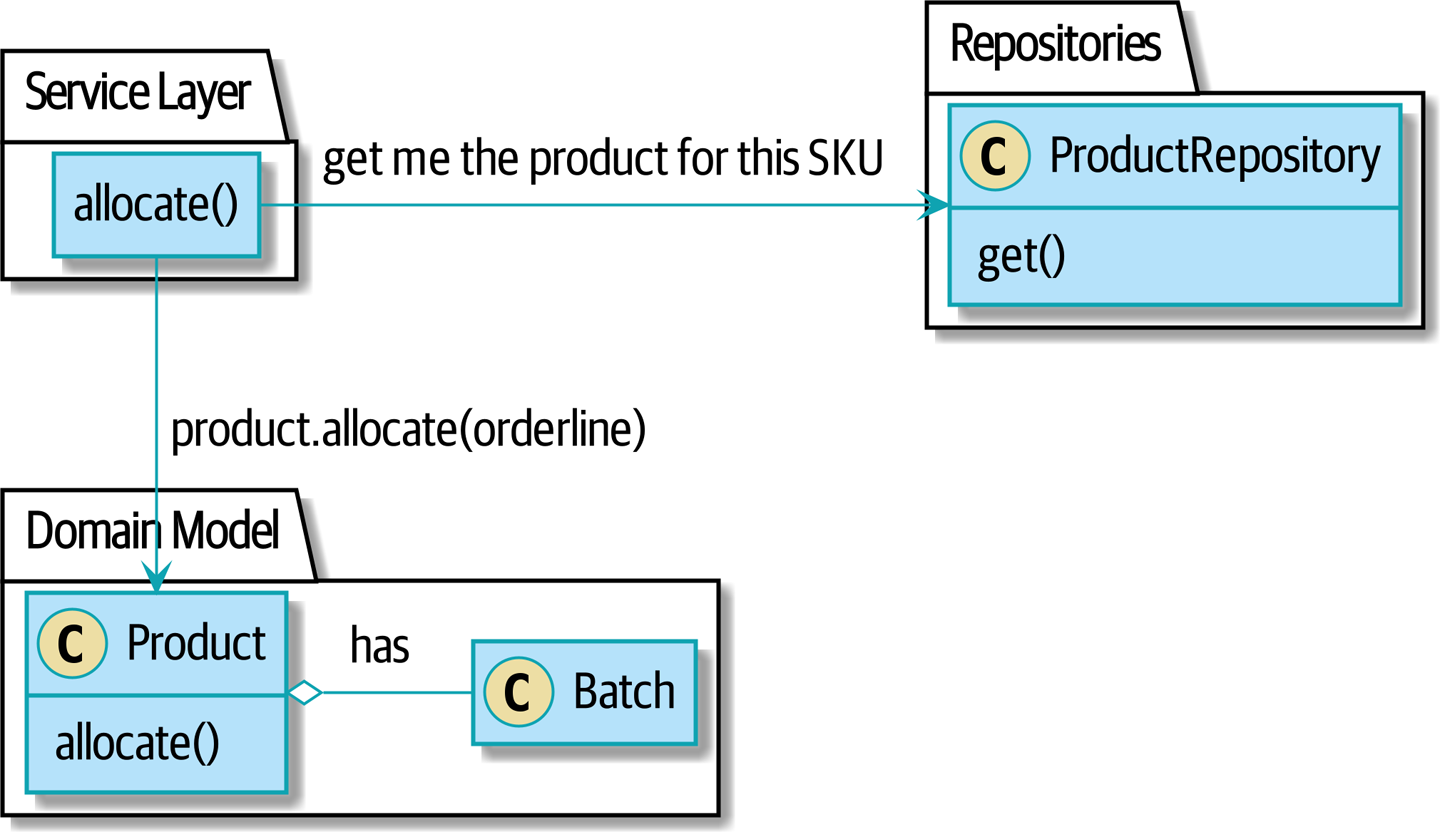
코드를 보자.
class Product:
def __init__(self, sku: str, batches: List[Batch]):
self.sku = sku #(1)
self.batches = batches #(2)
def allocate(self, line: OrderLine) -> str: #(3)
try:
batch = next(b for b in sorted(self.batches) if b.can_allocate(line))
batch.allocate(line)
return batch.reference
except StopIteration:
raise OutOfStock(f"Out of stock for sku {line.sku}")Product의 주요 식별자는sku다.Product클래스는 sku에 해당하는batches컬렉션 참조를 유지한다allocate()도메인 서비스를 이 애그리게이트가 제공한다.
Product는 통상 우리가 생각하는Product하고 좀 다르다… 가격도 없고 설명도 없고 크기도 없고…
하지만 현재 서비스에서는 그런 걸 고민할 필요가 없다. 이게 제한된 컨텍스트(이하 Bounded Context)의 강점이다. Bounded Context 상에서는 한 앱의 Product 개념이 다른 앱에서의 Product 와 완전히 다를 수 있다.
Aggregates, Bounded Contexts and Microservices
개념 소개 및 전개
이 개념은 근본적으로 전체 비즈니스를 한 모델에 넣으려는 시도에 대한 반응이었다. “고객” 이라는 컨텍스트를 가지고 이해해보자.
“고객” 이란 단어도 각 분야별 사람들에겐 각자 다른 의미를 가진다(판매상에서의 고객, CS에서의 고객, 배송에서의 고객, 지원에서의 고객 등). 그러니 각 “고객”의 속성이나 의미는 분야(컨텍스트)가 달라지면 완전히 다른게 되어버림을 알 수 있다.
이런식으로 모든 유스케이스를 잡아내는 단일 모델(클래스, DB 등)을 만드는 대신 여러 모델을 만들고 각 컨텍스트 간의 경계(Bounded Context)를 잘 잡은 후 여러 컨텍스트를 왔다갔다 할 때 명시적인 변환을 처리하자는 아이디어가 도출되었다.
그러니 자연스럽게 마이크로서비스가 대두된다. 각 마이크로서비스가 각자 자유롭게 “고객” 개념을 가지고, 자신이 통합해야 하는 다른 마이크로서비스의 개념으로 변환해 가져오거나 내보낼 수 있다.
(대충) 예시로 살펴보자
할당 서비스 에서는 Product(sku, batches) 가 있을 수 있을 것이고, 어떤 전자상거래의 Product 라면 Product(sku, description, price, image_url, dimensions, ...) 가 있을 수 있을 것이다. 내가 앞으로 작성해야 할 도메인 모델은 오직 내가 계산을 수행하기 위한 필요 데이터만을 포함해야 한다!
마이크로서비스를 떠나서, 애그리게이터를 선택할 때는 어떤 제한된 컨텍스트 안에서 애그리게이트를 실행할지 선택해야 한다. 컨텍스트를 제약하면 애그리게이트의 숫자를 낮게 유지하고 그 크기를 관리하기 좋은 크기로 유지할 수 있다.
나중에 아래 책들을 꼭 사서 보자…5
- 반 버논, <도메인 주도 설계 핵심> (에이콘출판사, 2017)
- 지금 이 책!
- 반 버논, <도메인 주도 설계 구현> (저자가 빨간 책이라 하는거) (에이콘출판사, 2016)
- 에릭 에반스, <도메인 주도 설계> (저자가 파란 책이라 하는거) (위키북스, 2022)
7.5 One Aggregate = One Repository
애그리게이트가 될 엔티티를 정의하고 나면 외부 세게에서 접근할 수 있는 유일한 엔티티가 되어야 한다는 규칙을 적용해야 한다. 허용되는 모든 저장소는 오직 애그리게이트만을 반환해야 한다.
저장소가 애그리게이트만 반환해야 한다는 규칙은 애그리게이트가 도메인 모델에 접근하는 유일한 통로라는 관례를 지키도록 하는 핵심 규칙이다. 이를 어기지 말자!
시작해보자!
그러면 기존에 있던 BatchRepository 는 ProductRepository 가 될 것이다. 천천히 코드를 갈아보자…
- UoW와 저장소 객체를 살펴보자
class AbstractUnitOfWork(abc.ABC):
products: repository.AbstractProductRepository
...
class AbstractProductRepository(abc.ABC):
@abc.abstractmethod
async def get(self, reference) -> List['Product']:
raise NotImplementedError
@abc.abstractmethod
async def add(self, product: 'Product'):
raise NotImplementedErrorORM계층을 조절해서 올바른 배치를 가져오게 한 후 Product 객체와 연관시켜야 한다. Repository 패턴을 쓰면 이를 어떻게 연관시킬지 아직 신경쓰지 않아도 된다. FakeRepository 를 쓰고 새 모델을 서비스 계층으로 전달해서 Product 가 엔트리포인트인 경우 서비스 계층이 어떤 모습일지 코드로 볼 수 있다.
- 서비스 계층의 변화를 살펴보자
- 의외로 쉽게 갈아끼워진다! 서비스 계층에서 서비스”만”을 바라보도록 코드를 작성한 도움인 것 같다.
async def add_batch(
ref: str,
sku: str,
qty: int,
eta: Optional[date],
uow: unit_of_work.AbstractUnitOfWork
):
async with uow:
product = uow.products.get(sku=sku)
if product is None:
product = model.Product(sku=sku, batches=[])
uow.products.add(product)
await product.batches.add(model.Batch(ref, sku, qty, eta))
await uow.commit()
async def allocate(
orderid: str,
sku: str,
qty: int,
uow: unit_of_work.AbstractUnitOfWork
) -> str:
line = model.OrderLine(orderid, sku, qty)
async with uow:
product = await uow.products.get(sku=line.sku)
if product is None:
raise InvalidSku(f'Invalid sku {line.sku}')
batchref = product.allocate(line)
await uow.commit()
return batchref
async def deallocate(
orderid: str,
sku: str,
qty: int,
uow: unit_of_work.AbstractUnitOfWork,
):
line = model.OrderLine(orderid, sku, qty)
async with uow:
product = await uow.products.list()
if product is None:
raise InvalidSku(f'Invalid sku {line.sku}')
model.deallocate(line, product)
await uow.commit()7.6 성능은 어떨까?
저자가 성능좋은 소프트웨어를 원하기 때문에 애그리게이트로 모델링한다고 여러 번 말했다. 근데 배치 하나만 요청해도 모든 배치를 읽어온다. 그럼 안 좋은거 아닌가? 라고 생각했는데 근거가 있다:
- 현재는 의도적으로 DB질의를 한 번만 하고 변경된 부분을 한 번만 영속화하여 데이터를 모델링하는 기법을 사용중이다. 이런 방식은 소프트웨어가 진화하면 할 수록 여러번 다양한 질의를 던지는 프로그램보다 시스템 성능이 나은 경향이 있다.
- 데이터 구조를 최소한으로 쓰며 한 row 당 최소한의 문자열과 정수만 만든다. 이러면 수백개의 배치를 메모리로 가져올 수 있다.
- 시간이 지나도 가져오는 데이터의 양은 제어를 벗어나지 않는다.
예를 들어 어느 시점에서는 상품마다 20개 정도의 배치가 있을 것이라 “예상” 한다. 배치를 다 사용하고나면 이 배치를 계산에서 배제할 수 있다. 4. 만일 상품 당 몇천 개의 배치가 있다 예상된다면 배치의 로드방식을 lazy-loading(지연 읽기)으로 처리한다. SQLAlchemy는 이미 데이터를 페이지 단위로 읽어온다. 이렇게 하면 적은 수의 row를 가져오는 DB요청이 더 많아진다. 이렇게 점진적으로 행을 가져오는 방식도 잘 작동한다.
코드를 짜보자.
그리고, 다른 모든 방법이 실패하면 다른 애그리게이트를 살펴본다.
- 어쩌면 배치를 지역/창고별로 나눠야할 수도 있다
- 아니면 선적이라는 개념을 중심으로 데이터 접근전략을 재설계 해야할 수도 있다
애그리게이트 패턴은 일관성과 성능을 중심으로 여러 기술적 제약사항을 관리하는데 도움이 되도록 설계된 패턴이다. 올바른 애그리게이트가 하나만 있는 것은 아니다. 설정한 경계가 성능을 떨어뜨린다면 언제든 설계를 다시 할 준비를 하자. 바꿔도 좋다. 언제든 바꿀 수 있다고 생각하고, 또 이게 편하다고 느껴야 한다.
7.7 버전 번호와 낙관적 동시성
DB 수준에서 데이터 일관성을 강제할 수 있는 방법을 더 살펴보자
이번 절(section)에서는 구현을 다룬다. 또한 Postgres-specific 코드다.
여러 접근방법 중 하나일 뿐이다.
실전에서는 요구사항 별로 다르게 접근해야할 수도 있다. 코드를 절대 프로덕션에 복붙하지 마시오.
전체 batches 테이블에 락걸고 싶지는 않고 특정 SKU에 해당하는 행에만 lock을 걸 수 있을까?
한가지 답은 Product 모델 속성 하나를 사용해 전체 상태 변경이 완료되었는지 표시하고, 여러 동시성 작업자들이 이 속성을 획득하기 위해 경쟁하는 자원으로 활용하는 방법이다. 두 트랜잭션이 batches 에 대한 세계 상태를 동시에 읽고 둘 다 allocation 테이블을 업데이트 하려고 한다면, 각 트랜잭션이 product_table 에 있는 version_number 를 업데이트하도록 강제할 수 있다. 이러면 경쟁하는 트랜잭션 중 하나만 승리하고, 세계가 일관성 있게 남게 된다.
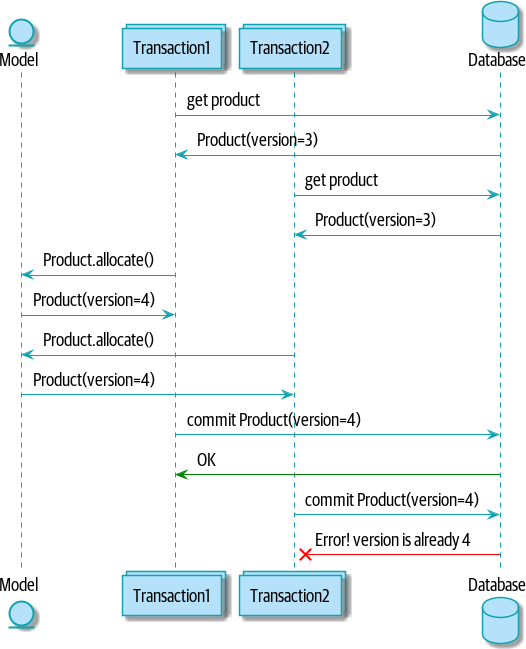
- 둘 다 버전
3을 가져간다 - 모델에 allocate을 하면 버전
4를 담고있는 Product 객체가 생긴다- 해당 객체를 먼저 커밋한 사항이 반영된다
- 늦게 커밋한 사람은 버전이 안맞아서 못 한다. 혹은 다시 하거나
낙관적 동시성 제어와 재시도
어쨌거나 성능과 충돌 가능성을 측정 후 어떤 정책을 가져가야 할지 평가해야 한다.
- 낙관적/비관적 동시성 제어에 대해
- 낙관적 동시성 제어(Optimistic Concurrency Control)
- 여러 사용자의 DB 변경 충돌이 드물 것이다 라고 생각한다
- 일단 업데이트 하고 문제 시 통지받을 수 있는 방법이 있는지만 확실히 한다
- 충돌 발생 시 어떻게 처리해야 할지 명시해야 한다
- 비관적(pessimistic) 동시성 제어
- 여러 사용자의 DB 변경 충돌이 잦을 것이다 라고 가정한다
- 모든 충돌을 피하려 노력하고, 안전성을 위해 모든 대상을 lock을 사용해 잠근다
- 실패 처리는 DB가 해줘서 고민할 필요는 없지만, deadlock을 고민해봐야 한다
- E.g.,
batches테이블 전체를 lock 걸거나,SELECT FOR UPDATE를 사용한다.
- 낙관적 동시성 제어(Optimistic Concurrency Control)
- 실패 처리에 대한 방안
- 실패한 연산을 처음부터 다시 함
- 두 트랜잭션 예시에서 실패한 쪽은 다시 요청해서 결과를 받아본다
- 실패한 연산을 처음부터 다시 함
7.7.1 버전 번호를 구현하는 방법
- 도메인의
version_number를 사용- 해당 값을
Product생성자에 추가하고Product.allocate()가 버전 번호를 올리는 경우
- 해당 값을
- 서비스 계층이 수행
- (근거) 버전 번호는 도메인의 관심사가 아니기 때문이다
- 따라서 서비스 계층에서
Product에 저장소를 통해 버전번호를 덧붙이고,commit()전에 버전 번호를 증가한다고 가정할 수 있다
- 인프라와 측에서 사용(controversial)
- (근거) 버전 번호는 결국 인프라와 관련있다
- 따라서 UoW와 저장소가 처리한다
- 저장소는 자신이 읽어 온 상품의 모든 버전 번호에 접근 가능하다
- UoW는 상품이 변경됐다는 가정 하에 자신이 아는 상품의 버전 번호를 증가할 수 있다
3번 방법은 “모든” 제품이 변경되었다고 가정하지 않고서는 구현할 방법이 없다.
2번 방법은 상태 변경에 대한 책임이 서비스-도메인 계층 사이에 있어서 지저분하다(저자 曰)
도메인 관심사와 무관하게 가장 나은 방안이 1번 방안이다(저자 曰)
그럼 어디 둘까? 애그리게이트에 둔다.
class Product:
def __init__(
self,
sku: str,
batches: List[Batch],
version_number: int = 0,
):
self.sku = sku
self.batches = batches
self.version_number = version_number
def allocate(
self,
line: OrderLine,
) -> str:
try:
batch = next(b for b in sorted(self.batches) if b.can_allocate(line))
batch.allocate(line)
self.version_number += 1 # (1)
return batch.reference
except StopIteration:
raise OutOfStock(f"Out of stock for sku {line.sku}")
- 이 쯤 처리한다
- 참고: 버전 번호에 대해 고심하고있다면 “번호” 란 말이 그다지 중요하지 않다는 사실을 깨달으면 좋을 듯 하다.
- 중요한 점은
Product애그리게이트 변경 시ProductDB 컬럼이 변경된다는 사실이다. - 매번 임의로 UUID를 생성하거나, Snowflake ID6 같은 걸 쓰는건 어떨까 싶다.
7.8 데이터 무결성 규칙 테스트
이 대로 했을 때 의도대로 잘 되는지 살펴보자! 동시에 트랜잭션을 시도하면 모두 버전 번호를 올릴 수는 없으니 둘 중 하나는 실패할 것이다.
느린 트랜잭션7을 하나 임의로 만들어보자:
def try_to_allocate(orderid, sku, exceptions):
line = model.OrderLine(orderid, sku, 10)
try:
with unit_of_work.SqlAlchemyUnitOfWork() as uow:
product = uow.products.get(sku=sku)
product.allocate(line)
time.sleep(0.2)
uow.commit()
except Exception as e:
print(traceback.format_exc())
exceptions.append(e)어떻게 테스트하는지 살펴보자:
def test_concurrent_updates_to_version_are_not_allowed(postgres_session_factory):
sku, batch = random_sku(), random_batchref()
session = postgres_session_factory()
insert_batch(session, batch, sku, 100, eta=None, product_version=1)
session.commit()
order1, order2 = random_orderid(1), random_orderid(2)
exceptions = [] # type: List[Exception]
try_to_allocate_order1 = lambda: try_to_allocate(order1, sku, exceptions)
try_to_allocate_order2 = lambda: try_to_allocate(order2, sku, exceptions)
thread1 = threading.Thread(target=try_to_allocate_order1) #(1)
thread2 = threading.Thread(target=try_to_allocate_order2) #(1)
thread1.start()
thread2.start()
thread1.join()
thread2.join()
[[version]] = session.execute(
"SELECT version_number FROM products WHERE sku=:sku",
dict(sku=sku),
)
assert version == 2 #(2)
[exception] = exceptions
assert "could not serialize access due to concurrent update" in str(exception) #(3)
orders = session.execute(
"SELECT orderid FROM allocations"
" JOIN batches ON allocations.batch_id = batches.id"
" JOIN order_lines ON allocations.orderline_id = order_lines.id"
" WHERE order_lines.sku=:sku",
dict(sku=sku),
)
assert orders.rowcount == 1 #(4)
with unit_of_work.SqlAlchemyUnitOfWork() as uow:
uow.session.execute("select 1")- 원하는 동시성 행동 방식을 잘 재현할 수 있는 두 스레드를 실행시킨다.
read1,read2그리고write1,write2
- 버전 번호가
1오른 것을 확인한다 - 필요하면 이런 식으로 확인한다
allocate()이 하나만 되었음을 검사한다
7.8.1 DB 트랜잭션 격리 수준을 사용하여 동시성 규칙을 강제
- (Postgres 에만 국한되는건 아니지만) 트랜잭션 격리 수준을
REPEATABLE READ로 조절한다. 상세한 정보는 Postgres 공식 문서를 읽자
DEFAULT_SESSION_FACTORY = sessionmaker(
bind=create_engine(
config.get_postgres_uri(),
isolation_level="REPEATABLE READ",
)
)7.8.2 비관적 동시성 제어 예제: SELECT FOR UPDATE
해당 방안은 비관적 동시성 제어 방안 중 하나이다. SELECT FOR UPDATE 8는 두 트랜잭션이 동시에 같은 row를 읽도록 허용하지 않는다.
SELECT FOR UPDATE 는 lock으로 사용할 row를 선택하는 방안이다(업데이트 대상 row일 필요는 없다). 두 트랜잭션이 동시에 SELECT FOR UPDATE 를 수행하면 두 업데이트 중 하나만 승리하고 나머지는 상대방이 lock을 풀 때 까지 기다려야 한다. 이는 동시성 패턴을 아래와 같이 바꾼다.
AS-IS
read1, read2 , write1, write2(fail)
TO-BE
read1, write1, read2, write2(succeed)
이걸 “Read-Modify-Write” failure mode 라고 부르는 사람도 있다. 아래 게시글을 읽고 통찰을 얻자!
“PostgreSQL Anti-Patterns: Read-Modify-Write Cycles”
REPEATABLE READ 나 SELECT FOR UPDATE 어떤걸 하든 트레이드오프가 있다. 상기 테스트코드와 같은 접근을 하면 어떤 식으로 바뀌는지 알 수 있다. 물론 테스트코드를 더 좋게 보강해야겠지만…
동시성 제어를 어떻게 할지는 비즈니스 환경, 저장소 기술에 따라 달라진다.
7.9 마치며
이번 장은 애그리게이트의 개념을 살펴봤다.
애그리게이트는…
- 모델의 일부 부분집합에 대한 주 진입점 역할을 한다
- 모든 모델 객체에 대한 비즈니스 규칙과 불변조건을 강제하는 역할을 담당하도록 객체를 명시적으로 모델링한다
올바른 애그리게이트를 잘 선택해야 한다! 시간이 지나고 요구사항 등등 재검토를 수행하다 보면 애그리게이트로 고른 객체가 달라질 수도 있다.
이 링크를 꼭 읽어보자. 존 버넌이 효과적인 애그리게이트 설계에 대해 쓴 글이다.
그러면 이어서, 애그리게이트의 트레이드오프에 대해 살펴보자.
| 장점 | 단점 |
|---|---|
| 애그리게이트는 도메인 모델 클래스 중 어떤 부분이 공개되어있고, 어떤 부분이 비공개인지 결정할 수 있다(멤버함수, 멤버변수에 _ 하나를 붙여서) | 엔티티, VO를 적당히 잘 감싼 객체가 또 하나 생긴다. 솔직히 이해하기 너무 어렵다…. |
| 연산 주변에 명시적인 Bounded Context를 모델링할 수 있으면 ORM 성능 문제 예방에 도움된다 | 한번에 한 가지 애그리게이트만 변경할 수 있다는 규칙을 엄격히 지키도록 해야하는데, 그것도 정말 어렵다… |
| 애그리게이트는 자신이 담당한 모델에 대한 상태변경만을 책임지도록 하면 시스템 추론 및 불변조건 제어가 쉬워진다 | 애그리게이트 사이의 최종 일관성을 처리하는 과정이 복잡해질 수 있다. 와 정말 너무 어렵다………… |
7.9.1 애그리게이트와 일관성 경계
- 애그리게이트는 도메인 모델에 대한 진입점이다
- 도메인에 속한 것을 바꿀 수 있는 방식을 제한하면 시스템을 더 쉽게 추론할 수 있다
- 애그리게이트는 Bounded Context를 책임진다
- 애그리게이트의 역할은 여러 객체로 이루어진 그룹에 적용할 불변조건에 대한 비즈니스 규칙을 관리하는 것이다
- 자신이 담당하는 객체 사이와 객체와 비즈니스 규칙 사이의 일관성을 검사하고, 어떤 변경이 일관성을 해친다면 이를 거부하는 것도 애그리게이트의 할 일이다.
- 애그리게이트와 동시성 문제는 공존한다
- 동시성 검사 구현 방안을 고민하면 자연스럽게 트랜잭션과 lock까지 간다. 이는 성능과 직결된 이야기다
- 애그리게이트를 제대로 고르는 것은 도메인을 개념적으로 잘 조직화하는 것 뿐 아니라 성능까지 살펴보는 것이다
7.10 1부 돌아보기
아무리 예제를 베끼고 내가 짜야할 것들을 짜고 했지만 이걸 만들다니….
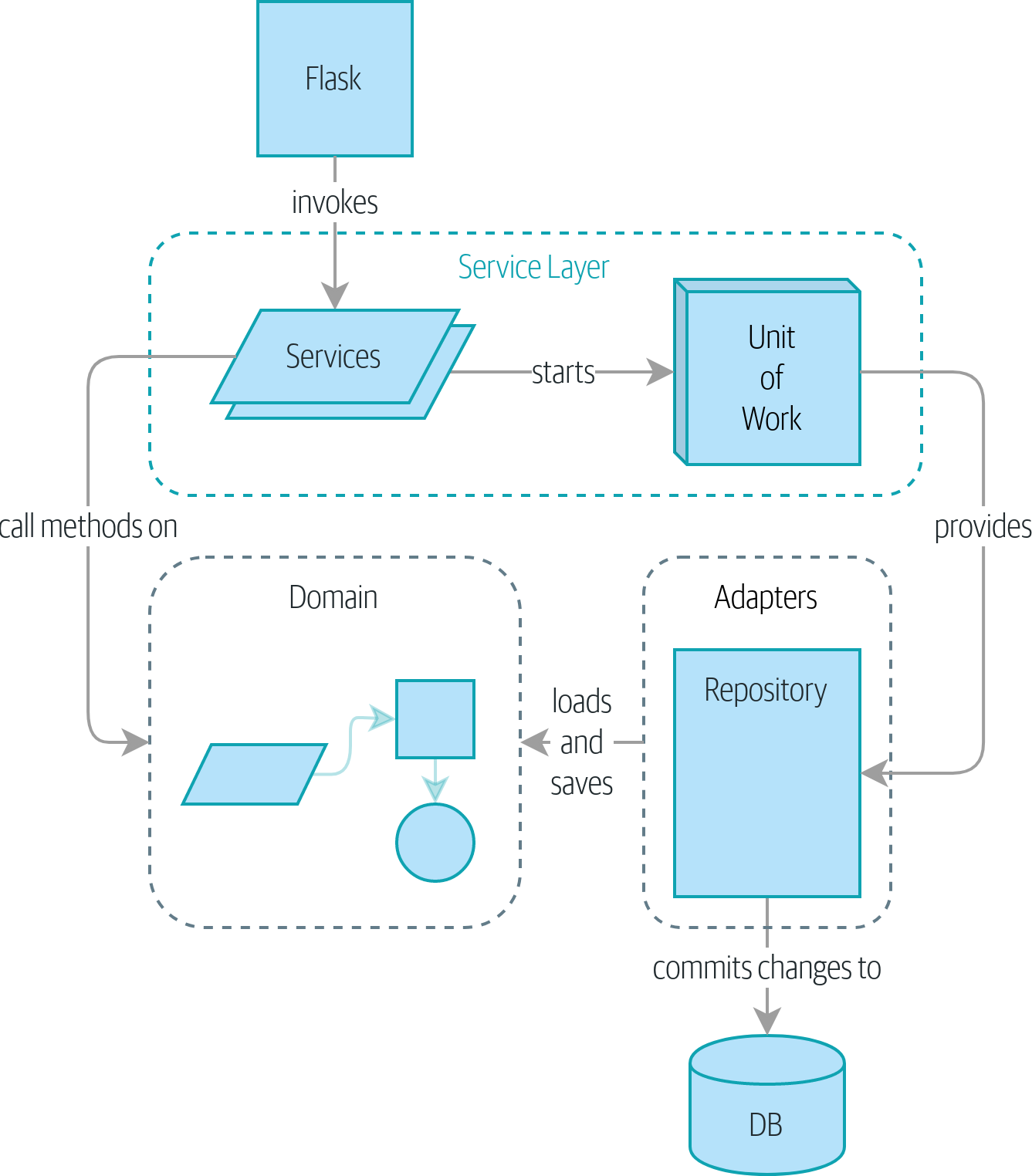
뭘 만들어낸건지 리뷰해보자.
- 테스트 피라미드 → 검증된 도메인 모델 생성
- 비즈니스 요구사항에 맞게 시스템이 어떻게 도는지를 코드로 작성했다
- 비즈니스 요구사항이 바뀌면 테스트도 마찬가지로 변하면 된다
- API 핸들러, DB 등의 구조를 분리했다
- 애플리케이션 외부에서 하부구조를 끼워넣을 수 있게 만들었다
- 코드 베이스의 조직화가 이루어졌다
- DIP를 적용했다. 포트와 어댑터에서 영향받은 “저장소” 와 UoW를 사용했다
- 저장소 수준의 테스트코드와 UoW 수준의 테스트코드를 분리했다
- 시스템의 한쪽 끝부터 다른쪽 끝까지 테스트했다
- Bounded Context
- 변경이 필요할 때마다 전체 시스템을 잠그고 싶지않아서, 어떤 부분에 대해서만 일관성을 가지는지를 나눴다
2부에서는 모델을 넘어서는 일관성을 처리하기 위한 방안을 살펴볼 것이다.
경고!
이런 패턴이 하나씩하나씩 붙을 때 마다 전부 비용이다.
간접계층 하나하나가 모두 비용이다. 이 패턴을 모르는 사람에게 혼동을 야기할 수 있다. 이것도 큰 비용이다. 만약 만들 앱이 DB를 단순히 감싸는 CRUD wrapper 라면? 앞으로 이것 외의 일을 할 것 같지 않다면?
이런 복잡한걸 쓸 필요가 없다.
- 왠지 이 책의 3장을 다시 읽어봐야할 것 같은 느낌이다. 저기서 본 내용들의 일부가 여기도 나온다.↩
- 할당 후 배치의 가용 재고 수량이 라인의 상품 수량만큼 감소하므로 비즈니스 제약 사항을 만족한다면 항상 가용 재고 수량은
0보다 크거나 같다.↩ - 이 코드의 모델의 경우 배치가 컬렉션이다.↩
- A product is identified by a SKU, … 하면서 이미 풀어놨음↩
- 이 분의 블로그 게시글을 보고 뽐뿌가 왔다… 꼭 지식을 머리속에 집어넣도록 하자↩
- https://en.wikipedia.org/wiki/Snowflake_ID 를 의미한다↩
- 동시성 버그 재현을 위해 스레드 사이에서 세마포어나 비슷한 동기화 기능을 쓰는 편이 테스트 행동 방식을 보다 잘 보장할 수 있다.↩
- https://www.postgresql.org/docs/current/explicit-locking.html↩