파이썬으로 살펴보는 아키텍처 패턴 (12)
이 내용은 “파이썬으로 살펴보는 아키텍처 패턴” 을 읽고 작성한 내용입니다. 블로그 게시글과, 작성한 코드를 함께 보시면 더욱 좋습니다.
12장은 해당 코드를 살펴봐주세요. 코드 링크
12장 Command-Query Responsibility Segregation (CQRS)
읽기-쓰기 가 다른 작업이라는 것은 누구나 알고있다. 그런 고로 이에 대한 책임을 분리할 필요가 있다. 굳이 이런 짓을 왜 하는지 살펴보자!
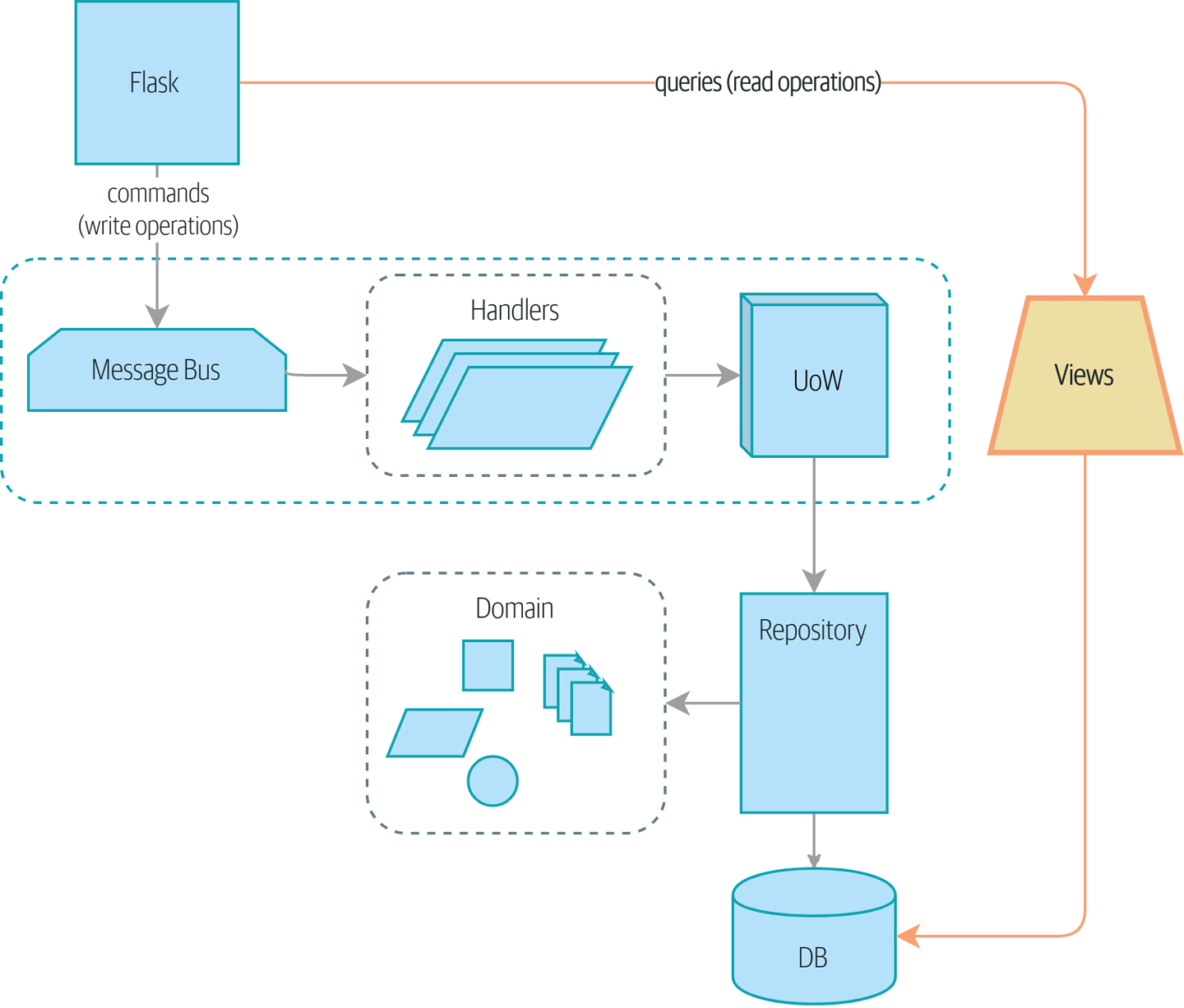
12.1 쓰기 위해 존재하는 도메인 모델
도메인 규칙을 강화하는 소프트웨어를 만드는 방법에 대해 여태 학습해왔다. 이런 규칙이나 제약은 앱마다 다르고 시스템마다 다르다.
책에서는 ‘현재 사용가능한 재고보다 더 많은 재고를 할당할 수 없다 (can_allocate())’ 같은 명시적 제약을 만들거나, 각 주문 라인은 한 배치에 해당된다 같은 암시적 제약(allocate 메소드의 행위 자체를 통해)을 걸었다.
이런걸 제대로 하려면 연산의 일관성(UoW 패턴)을 보장하며, 각 연산 자체는 객체 단위에서 수행하도록 해야했다(애그리게이트 패턴).
그리고, 작업 덩어리 사이에서 변경된 내용을 통신하기 위해 도메인 이벤트 패턴을 도입하였다. 이를 통해 ‘재고 손상/분실 시, 배치의 사용가능수량을 조절하고 필요하다면 주문을 재할당하시오’ 같은 규칙을 정할 수 있었다(change_batch_quantity 로직과, 메시지 버스(MessageBus) 상의 commands.ChangeBatchQuantity 커맨드 같은 것을 의미함).
이런 복잡도는 시스템 상태를 변경할 때 규칙적용을 강화하기 위해 존재한다. 즉 데이터를 유연하게 쓰기 위한 도구를 만든 것이다.
그렇다면 읽기는?
12.2 가구를 구매하지 않는 사용자
저자가 개발중인 시스템(책에선 메이드닷컴이라 나옴)에는 할당 서비스도 있을 것이다. 시간당 100건 넘는 주문도 처리한다. 그렇지만 재고를 할당해주는 시스템이 존재한다.
하지만 같은 날에 제품 뷰에 대한 건수는 초당 100건에 달할 수 있다. 재고가 있나 보거나, 배송이 얼마나 오래걸리는지 걸리기 위해 누군가 상품 목록 페이지나 상품페이지에서 하염없이 F5만 때리고 있을지도 모른다.
도메인은 똑같다. 재고 배치, 배치의 도착일, 사용 가능한 수량에 대해 관심이 있다. 하지만 접근 패턴은 매우 다르다. 요컨대 고객은 쿼리가 몇 초 지난 상태인지 알 수 없다. 그렇지만 할당 서비스가 일관성이 없는건 고객 주문이 꼬여지는 것을 의미한다. 이런 차이를 십분 활용하여 읽기에 대해선 최종적으론 일관성있게(eventually consistent) 유지하여 성능을 향상시킬 수 있다.
12.2.1 읽기 일관성을 정말로 달성할 수 있을까?
일관성과 성능을 맞교환하는 사실은 받아들이기 어렵다. 당연히 갖춰야한다. RDBMS에 저장된 값이 다르다를 상상할 수 있을까?
그런데 읽기 데이터에 대한 생각을 조금만 바꿔보면 읽어온 데이터는 그 시점에만 최신이다. 그리고 분산 시스템은 완전한 일관성을 갖출 수 없다. 시스템의 현재 상태를 계속해서 검사해야한다. 관점을 바꾸기 위한 예를 들어보자.
- A라는 고객이 ‘가’ 라는 상품이 “재고있음” 이란 것을 보고 잠깐 자리를 비운 새 B라는 고객이 먼저 구매해버렸다고 하자. A라는 고객이 다시 요청하면, 재고가 없어서 (1) 주문을 취소하거나 (2) 더 많은 재고를 요청하여 A 고객이 주문한 상품의 배송을 늦춘다.
- 어찌어찌해서 완전한 일관성을 보장하는 웹앱이 생겼다고 하자. A라는 고객이 제품 구매를 하였으나, 배송중 제품이 박살나버렸다. 이러면 결국 (1) 환불처리를 하거나 (2) 더 많은 재고를 요청하여 A 고객이 주문한 상품의 배송을 늦춘다.
이렇듯 현실은 소프트웨어 시스템과 일관성이 없으므로, 비즈니스 프로세스는 이런 경우를 처리할 수 있어야 한다. 다시말해 일관성이 없는 데이터는 근본적으로 피할 수 없으므로 읽기 측면에서 성능과 일관성을 어느정도 바꾸어도 좋다.
12.2.2 읽기와 쓰기 비교
이런즉 시스템은 ‘읽기’와 ‘쓰기’ 두 시스템으로 분할이 가능하다.
쓰기쪽에서 채택한 도메인 아키텍처 패턴은 읽기에 큰 도움이 되지 않는다. 그래서 배워야함ㅋㅋ
| 읽기 | 쓰기 | |
|---|---|---|
| 동작 | 간단한 읽기 | 복잡한 비즈니스 로직 |
| 캐시 가능성 | 높음 | 캐시 불가능 |
| 일관성 | 오래된 값 제공 가능 | 트랜잭션 일관성이 있어야 함 |
12.3 POST/리디렉션/GET과 CQS
웹 개발을 하는 사람에겐 POST/리디렉션/GET패턴이 익숙할 것이다1. 이 기법에서 웹 엔드포인트는 POST 콜을 받고 처리결과를 보여주기 위해 리디렉션으로 응답한다. 책의 예시를 말해보자면 POST /batches 를 해서 배치를 만들면 GET /batches/123 으로 리디렉션해서 새 배치를 보여준다거나… 하는 것이다. 요는 연산의 쓰기와 읽기 단계를 분리하여 문제를 해결했다는 점이다.
이 기법은 명령-쿼리 분리(Command-Query Separation, CQS) 의 예시이다. CQS에서는 한가지 간단한 규칙을 따른다. 함수는 상태변경 혹은 질의응답 둘 중 하나만 해야한다. 둘 다 해서는 안된다. 이러면 소프트웨어 추론이 쉬워진다. 전등을 껐다켰다 하지 않아도 전등이 켜져있나? 라는 질문에 답할 수 있어야 한다.
📒 NOTE
API 생성시에도 Location 헤더가 새로운 자원의 URI를 포함하면 201 Created 혹은 202 Accepted를 반환함으로써 같은 설계기법을 사용한다.
여기서는 사용하는 상태코드의 값이 아니라 논리적으로 읽기-쓰기를 분리했다는 점을 캐치하자.
기존코드의 CQS 위반부분을 먼저 해결하자. 오래 전에 주문을 받아 서비스 계층을 호출하여 재고를 할당하는 allocate 이란 엔드포인트를 바꾸자. 기존에는 호출 시 200 OK와 배치 ID를 반환했는데, 이러한 읽기-쓰기가 혼재된 부분을 해소해보자. 우선 테스트코드부터…
@pytest.mark.asyncio
@pytest.mark.integration
async def test_happy_path_returns_202_and_batch_is_allocated(
async_engine,
client,
clear,
):
orderid = random_orderid()
sku, othersku = random_sku(), random_sku('other')
...
data = OrderLine(orderid=orderid, sku=sku, qty=3)
res = await client.post("/allocate", json=asdict(data))
assert res.status_code == status.HTTP_202_ACCEPTED # 1)
res = await client.get(f"/allocations/{orderid}")
assert res.json() == [{'sku': sku, 'reference': earlybatch}] # 2)202 Accepted응답으로 오는지?GET /allocations/{order_id}로 호출했을 때 제대로 오는지?
본 로직은 이에 대응하여 어떻게 바뀌어지는지 보자
@app.post(
"/allocate",
status_code=status.HTTP_202_ACCEPTED, # 1)
)
@inject
async def allocate_endpoint(
...
@app.get(
"/allocations/{order_id}"
)
@inject
async def allocations_view_endpoint(order_id: str): # 2)
uow = unit_of_work.SqlAlchemyUnitOfWork(db)
result = views.allocations(order_id, uow) # 3)
if not result:
raise HTTPException(
status_code=status.HTTP_404_NOT_FOUND,
)
return result- 기존 정상리턴 코드는
202 Accepted로 바꿔준다 - 신규 API인
GET /allocations/{order_id}에 대해 엔드포인트를 만들어주자 - “읽기 전용” 이라는 의미에서
views.py로 파일명을 두자
12.4 잠깐만 있어보세요
repository 객체에서 값 목록을 리턴하는 메소드를 후딱 짜보자.
from sqlalchemy.sql import text
async def allocations(orderid: str, uow: unit_of_work.SqlAlchemyUnitOfWork):
async with uow:
results = await uow.session.execute(
text(
"""
SELECT ol.sku, b.reference
FROM allocations AS a
JOIN batches as b ON a.batch_id = b.id
JOIN order_lines AS ol ON a.orderline_id = ol.id
WHERE ol.orderid = :orderid
"""
),
dict(orderid=orderid),
)
return results.mappings().all()예제에서는 놀랍게도 쌩 쿼리(raw query)를 넣어놨다.
왜 이랬는지 보고, 실무에서는 보다 나은 트릭들을 써서 어떻게 하는지 보자
일단 뷰는 이런식으로 views.py 에 계속 보관하자
🍅 tips!
CQRS를 안하더라도 상태를 변경하는 커맨드와 이벤트 핸들러에서 읽기 전용 뷰를 분리하는게 좋다.
12.5 CQRS 뷰 테스트하기
뷰를 어떻게 가져가더라도 통합 테스트는 필요하다.
@pytest.mark.asyncio
async def test_allocations_view(sqlite_session_factory):
uow = unit_of_work.SqlAlchemyUnitOfWork(sqlite_session_factory)
await messagebus.handle(commands.CreateBatch('sku1batch', 'sku1', 50, None), uow)
await messagebus.handle(commands.CreateBatch('sku2batch', 'sku2', 50, today), uow)
await messagebus.handle(commands.Allocate('order1', 'sku1', 20), uow)
await messagebus.handle(commands.Allocate('order1', 'sku2', 20), uow)
# 제대로 데이터를 얻는지 보기 위해 여러 배치와 주문을 추가
await messagebus.handle(commands.CreateBatch('sku1batch-l8r', 'sku1', 50, today), uow)
await messagebus.handle(commands.Allocate('otherorder', 'sku1', 30), uow)
await messagebus.handle(commands.Allocate('otherorder', 'sku2', 10), uow)
assert await views.allocations('order1', uow) == [
{'reference': 'sku1batch', 'sku': 'sku1'},
{'reference': 'sku2batch', 'sku': 'sku2'},
]12.6 대안 1: 기존 저장소 사용하기
헬퍼 메소드를 products 저장소에 추가하면?
from pt2.ch12.src.allocation.service_layer import unit_of_work
from sqlalchemy.sql import text
async def allocations(
orderid: str,
uow: unit_of_work.SqlAlchemyUnitOfWork,
):
async with uow:
products = uow.products.for_order(orderid=orderid) # 1)
batches = [b for p in products for b in p.batches] # 2)
return [
{'sku': b.sku, 'batchref': b.reference}
for b in batches
if orderid in b.orderids # 3)
]
- 저장소는
Product객체를 반환하며 주어진 주문에서 sku에 해당하는 모든 상품을 찾아야한다. 저장소에.for_order()라는 헬퍼 메소드를 만든다 - 이 시점에서는 상품이 있지만 실제로 원하는 값은 배치에 대한 참조다. 그러므로 모든 배치를 가져온다
- 원하는 주문에 대한 배치만을 찾기 위해 다시 배치를 걸러낸다. 이 과정은 다시
Batch객체가 자신이 어떤 주문에 할당됐는지 알려준다는 사실에 의존한다
이 값은 Batch 객체에 .orderid 라는 프로퍼티를 구현하여 처리한다
이 방식은 기존 추상화를 재사용하는 장점이 있지만, 새 헬퍼 메소드를 저장소, 도메인 모델 클래스 둘 다에 추가하고 파이썬 수준에서 루프를 돌려야한다. DB를 쓰면 걍 쿼리로 하면 될 것인데 말이지.
12.7 읽기 연산에 최적화되지 않은 도메인 모델
가만보면 도메인 모델을 만드는데 든 노력은 주로 쓰기연산을 위한 것임을 알 수 있다. 그러니까 읽기를 위해서는 기존 추상화에 덧붙이고 파이썬 레벨에서 루프를 돌렸다.
그렇지만 이는 CQRS위해 골통을 짜맨 결과다. 도메인 모델은 앞서보았듯 데이터 모델이 아니다. 워크플로우, 상태 변경을 둘러싼 규칙, 메시지 교환 등 비즈니스의 규칙을 캐치하기 위한 요소였다. 이는 시스템이 외부 이벤트와 입력에 대해 어떻게 처리하는지에 대한 내용이다. 이 요소중 대부분은 읽기 전용 연산과는 관계가 없다.
🍅 tips!
CQRS가 필요하다고 말하는 것은 도메인 모델 패턴이 필요하다고 하는 것과 연관있다. 단순 CRUD앱은 읽기/쓰기가 밀접하게 연관되어있기 때문에 도메인 모델이나 CQRS가 필요없지만, 도메인이 복잡해지면 도메인 모델과 CQRS 모두가 더 많이 필요해진다.
접근 편의를 위해 도메인 클래스는 상태를 변경하는 메소드를 여럿 제공하지만, 읽기 전용 연산에서는 이런게 모두 필요하지 않다.
게다가 도메인 모델의 복잡도가 더 커질 수록 모델을 구성하는 방법에 대한 선택의 폭이 넓어진다. 따라서 읽기 연산에 도메인 모델을 사용하는 것이 더 어려워진다.
12.8 대안 2: ORM 쓰기
테스트코드가 살짝 바뀐다
@pytest.mark.asyncio
async def test_allocations_view(sqlite_session_factory):
uow = unit_of_work.SqlAlchemyUnitOfWork(sqlite_session_factory)
await messagebus.handle(commands.CreateBatch('sku1batch', 'sku1', 50, None), uow)
await messagebus.handle(commands.CreateBatch('sku2batch', 'sku2', 50, today), uow)
await messagebus.handle(commands.Allocate('order1', 'sku1', 20), uow)
await messagebus.handle(commands.Allocate('order1', 'sku2', 20), uow)
# 제대로 데이터를 얻는지 보기 위해 여러 배치와 주문을 추가
await messagebus.handle(commands.CreateBatch('sku1batch-l8r', 'sku1', 50, today), uow)
await messagebus.handle(commands.Allocate('otherorder', 'sku1', 30), uow)
await messagebus.handle(commands.Allocate('otherorder', 'sku2', 10), uow)
view_result = await views.allocations('order1', uow) # 1)
expected = [
{'batchref': 'sku1batch', 'sku': 'sku1'},
{'batchref': 'sku2batch', 'sku': 'sku2'},
] # 2)
for data in expected:
assert data in view_result # 3)- 쿼리하면 다른 배치, 주문 내용도 다 나와버린다
- 내가 생각하는게 있는지 전체 배치와 주문 중에서 살펴봐야한다
- 따로 빼서 보면 된다
그렇다면 ORM을 써서 쿼리해버리면?
async def allocations(orderid: str, uow: unit_of_work.SqlAlchemyUnitOfWork):
async with uow:
batches = (
await uow.session.execute(
select(model.Batch)
.join(model.OrderLine, model.OrderLine.orderid == orderid)
)
).scalars() # 1)
return [
{'batchref': b.reference, 'sku': b.sku}
for b in batches
]- 비동기 쿼리는 SQLAlchemy 2.0 스타일의 ORM 쿼리를 짜야한다!
- 참고용 공식문서
- 이를 알게 된 스택오버플로우 게시글 → 공식문서의 출처
SQLAlchemy 문서를 보고 쿼리를 짜는건 크게 문제가 없으나, 성능상의 이슈가 있다.
12.9 SELECT N+1 과 다른 고려사항
SELECT N+12은 성능이슈가 생긴다. 객체 리스트를 가져올 때 ORM은 보통 필요한 모든 객체의 ID를 가져오는 쿼리를 먼저 수행한다. 그 후 각 객체의 어트리뷰트를 얻기 위한 개별 쿼리를 한다. 특히 객체에 외래키 관계가 많으면 더 자주 발생한다.
📒 NOTE
SQLAlchemy에서는 이를 피하기 위해 eager loading을 상황에 맞게 수행할 수 있다. 1.4 뿐 아니라 2.0에서도 문서를 꼭 읽어보자.
- SQLAlchemy 1.4에서의 관련 설명 - SQLAlchemy 2.0에서의 관련 설명
SELECT N+1 문제 외에도, 상태를 영속화하는 방법과 현재 상태 로드 방법을 분리해야하는 이유가 있다. 정규화된 테이블은 쓰기 연산이 데이터 오염을 발생시키는 것을 막는 방법이다. 그렇지만 읽어올 때 JOIN연산을 하면 읽기 연산이 느려질 수 있다.
이를 위해 정규화되지 않는 뷰를 추가하거나, 읽기 전용 복사본을 만들거나, 캐시 계층을 추가할 수 있다.
12.10 코드를 확 틀어보자3
12.4절에서 살펴본 코드를 정규화하지 않은 별도 뷰 모델에 값을 넣어버리고 그걸 바로 갖고오게 하자.
async def allocations(orderid: str, uow: unit_of_work.SqlAlchemyUnitOfWork):
async with uow:
results = await uow.session.execute(
text( # 1)
"""
SELECT sku, batchref
FROM allocations_view
WHERE orderid = :orderid
"""
),
dict(orderid=orderid),
)
return results.mappings().all()
allocations_view = Table( # 2)
'allocations_view',
metadata,
Column('orderid', String(255)),
Column('sku', String(255)),
Column('batchref', String(255)),
)- 전용 뷰에서 값을 가져오도록 하자
- 외래키 없이 그냥 바로 갖고올 수 있다.
읽기에 최적화된, 데이터의 정규화되지 않은 복사본을 만드는 방법도 나쁘지 않다. 인덱스를 사용해 처리할 수 있는 일의 한계가 생긴다면 이런 복사본을 만드는 방법이 있다. (저자 왈)사실 잘 튜닝한 인덱스라도 조인을 위해 CPU 사용량이 많다. 그런걸 놓고 보면 SELECT * FROM table WHERE key =: value 가 가장 빠르긴 하다.
이런 접근방식은 규모확장에도 장점을 가진다. RDBMS에 데이터를 쓸 때는 변경할 컬럼에 락을 걸어 일관성에 문제가 생기지 않도록 한다. 여러 클라이언트가 동시에 값을 변경하면 추적하기 힘든 race condition이 생긴다. 그렇지만 데이터를 읽을 때(reading)는 동시연산에 대한 제한이 없으므로 읽기 전용 저장소는 수평규모 확장이 가능하다.
🍅 tips!
읽기용 복사본이 일관성이 없을 수도 있어서, 사용할 수 있는 복사본 수에는 한계가 있다. 복잡한 데이터 저장소가 있는 시스템의 규모를 확장하는데 어려움이 있다면 더 간단한 읽기 모델을 만들 수 없는지 살펴보아야 한다.
그렇긴 하지만 이 읽기 모델을 최신상태로 유지하는 것도 어렵다. 데이터베이스 뷰(meterialized 하거나 그렇지 않거나)나 트리거가 일반적 해법이다. 하지만 이런 해법은 DB에 따라 한계가 정해진다. 아래에서는 DB 기능 대신 아키텍처 재활용을 살펴보도록 한다.
12.10.1 이벤트 핸들러를 사용한 읽기 모델 테이블 업데이트
Allocated 이벤트에 대해 두번째 핸들러를 넣는다.
Deallocated 이벤트도 마찬가지다.
읽기 모델의 시퀀스 다이어그램을 살펴보자
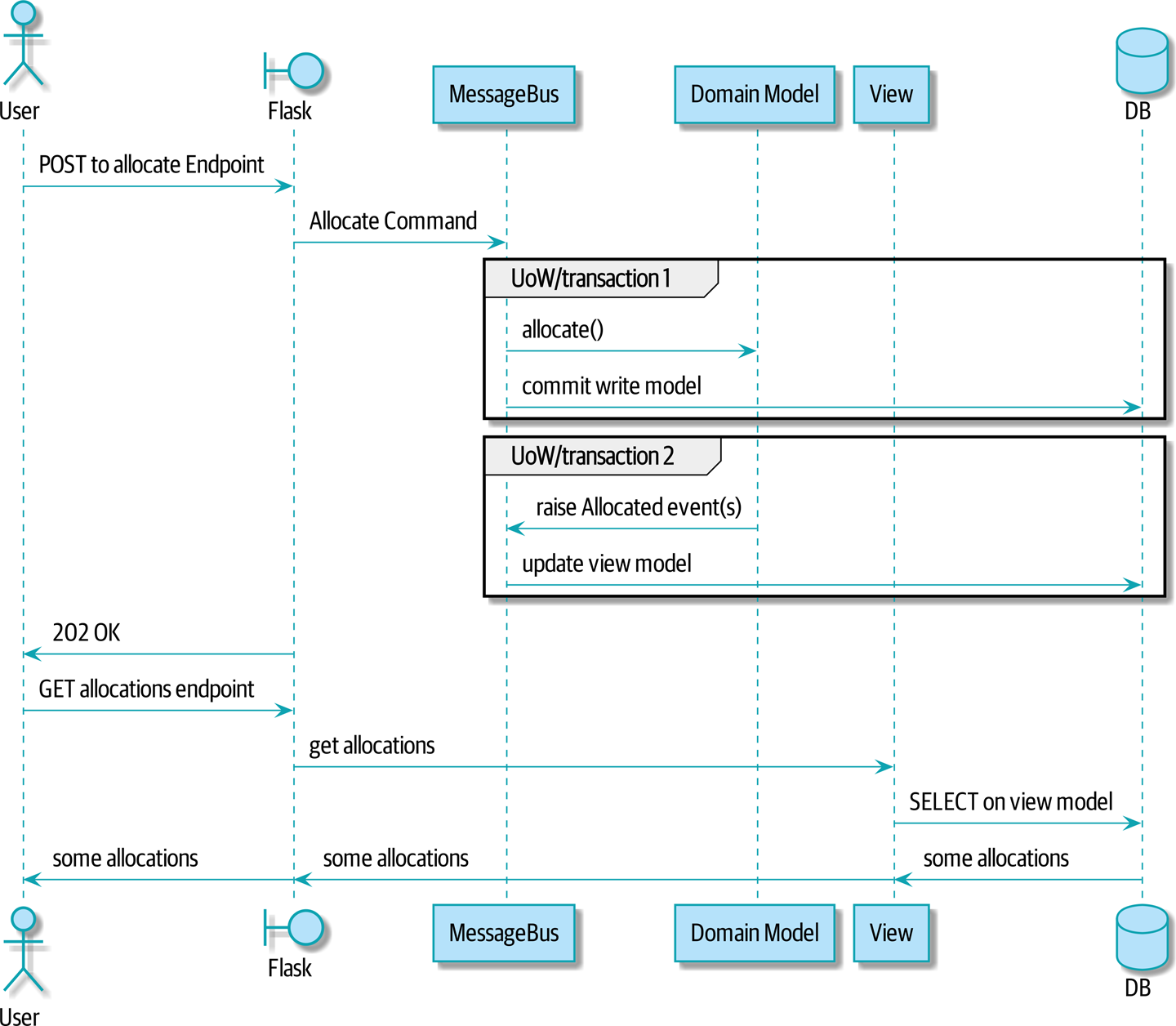
POST/쓰기 연산의 두 트랜잭션을 볼 수 있다.
- 쓰기 모델 업데이트
- 읽기 모델 업데이트
GET/읽기 연산은 이 읽기 모델을 사용한다.
12.11 읽기 모델 구현을 변경하기 쉽다
저장소 엔진을 바꿔버리면 어떻게 되는지 살펴보자.
- Redis 읽기 모델을 업데이트
- 관련 헬퍼메소드 작업
- Redis에 맞게 view를 변경
- 이 내용을 의미한다. 예를 들어서 유저가 POST로 보낸 값을 새로고침함하여 POST 요청을 또 보내는 문제에 대한 대처법으로도 사용된다.↩
- 쿼리 1번으로 N건을 가져왔으나, 관련 컬럼을 얻기 위해 쿼리를 N번 더 하는(!) 문제를 의미한다. 필히 알아둬야 할 내용이다. (N+1 쿼리문제 관련 링크)(교재상의 참고링크)↩
- Time to Completely Jump the Shark이 원제인데, jumping the shark은 잘 안풀려서 무리수를 뒀다 이런 뜻이라… (링크를 보고 알아서 판단하시와요)↩